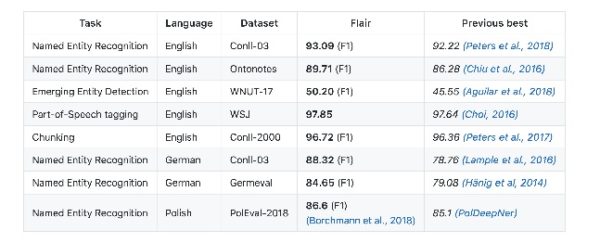
เนื่องในโอกาสของ Computer Science Education Week ทางนักวิจัยจาก Microsoft จึงได้ออกมาทำการทำนายเทคโนโลยีในอนาคต 17 ประการด้วยกัน

ก่อนจะเข้าถึงแนวโน้มเทคโนโลยี 17 ประการ ทาง Microsoft ได้ออกมาเล่าถึงรายงานและสถิติต่างๆ ที่เกี่ยวข้องก่อนดังนี้
ทั้งนี้เนื่องจาก Microsoft เองนั้นก็ต้องการที่จะร่วมเป็นหนึ่งในแรงผลักดันให้เกิดความเท่าเทียมทางเพศ และมีผู้หญิงที่มาทำงานในสายเทคโนโลยีกันมากขึ้นในอนาคต ทาง Microsoft จึงได้สัมภาษณ์นักวิจัยหญิง 17 คนใน Microsoft ถึงแนวโน้มในอนาคตเอาไว้ และทางทีมงาน TechTalkThai ก็ขอนำมาสรุปสั้นๆ เอาไว้ดังนี้
1. Kalika Bali: เทคโนโลยี Speech และ Language จะก้าวหน้าอย่างรวดเร็ว
เทคโนโลยีทางด้าน Speech และ Language จะพัฒนาและรองรับได้หลากหลายภาษามากขึ้นในปี 2017 และจะมีการพัฒนาเทคโนโลยีที่สามารถเข้าใจและโต้ตอบด้วยภาษาที่รองรับผู้ใช้งานได้มากขึ้น ไม่ว่าจะเป็นกลุ่มผู้ใช้ English-Spanish, French-Arabic หรือ Hindi-English ก็ตาม ส่วนภายในปี 2027 นั้นเทคโนโลยี Artificial Intelligence (AI) ทางด้านภาษาจะก้าวหน้าไปจนถึงขั้นเข้าใจในเหตุผลและสามารถสื่อสารกับมนุษย์ได้อย่างง่ายดายจนสามารถถกเถียงกันได้
2. Jennifer Chayes: Deep Learning จะก้าวหน้าและจัดการข้อมูลที่จะใช้ในการเรียนรู้ได้ดีขึ้น
เทคโลยีทางด้าน Deep Learning จะก้าวหน้ายิ่งขึ้นในปี 2017 ด้วยความรู้ความเข้าใจที่มากขึ้นและ Algorithm แบบใหม่ๆ ที่จะรวบรวมมาจากศาสตร์หลายๆ ด้าน รวมถึงการผนวกรวมศาสตร์ทางด้าน Statistical Physics และ Computer Science เข้าด้วยกัน ส่วนภายในปี 2027 นั้นชีวิตของเราทุกคนจะถูกปรับปรุงให้ดีขึ้นในทุกแง่มุมด้วยการมาของ Artificial Intelligence และ Machine Learning โดย Algorithm ภายในอนาคตนั้นจะสามารถตรวจสอบและจัดการกับ Input ที่ไม่ดีได้ด้วยตัวเอง เพื่อให้ในระบบมีเพียง Input ที่ดีสำหรับใช้ในการเรียนรู้ และสามารถตรวจสอบย้อนหลังได้
3. Susan Dumais: Deep Learning จะเข้าใจข้อมูลได้ดีขึ้น และการค้นหาข้อมูลจะเปลี่ยนรูปแบบไป
การนำ Deep Learning ไปใช้ในการค้นหาข้อมูลและการทำความเข้าใจกับข้อมูลในรูปของเอกสารนั้นจะพัฒนาไปเป็นอย่างมากในปี 2017 ส่วนในปี 2027 นั้นเราจะไม่เห็นกล่องสำหรับทำการค้นหากันอีกต่อไปแล้ว แต่เราจะสามารถทำการค้นหาข้อมูลได้ด้วยวิธีการอื่นๆ ที่หลากหลายมากยิ่งขึ้นแทน ไม่ว่าจะเป็นการพูด, การใช้รูปภาพ, การใช้วิดีโอ หรืออื่นๆ อีกมากมาย รวมถึงมีการนำ Context ต่างๆ ไปใช้ในการค้นหาได้หลากหลายยิ่งขึ้นด้วย
4. Sara-Jane Dunn: Biological Information Processing จะเข้ามามีบทบาทในการประมวลผลแห่งอนาคต
ทฤษฎีพื้้นฐานของการทำ Biological Information Processing จะเริ่มเกิดขึ้นมาในปี 2017 ทำให้เราสามารถนำไปต่อยอดเพื่อใช้ในการออกแบบ, ปรับแต่ง, และควบคุมพฤติกรรมของเซลล์ในการนำไปใช้ประมวลผลได้ ในขณะที่ปี 2027 นั้นเราจะเริ่มนำเทคโนโลยีเหล่านี้้ไปใช้งานได้ในอุตสาหกรรมที่หลากหลายทั้งการเกษตร, การผลิตยา ไปจนถึงพลังงาน, วัสดุศาสตร์ และการประมวลผล ทำให้มนุษยชาตินั้นเปลี่ยนจากยุคของการประมวลผลด้วย Silicon กลายไปเป็นการประมวลผลบน Software ที่มีชีวิต
5. Mar Gonzalez Franco: Virtual Reality จะเริ่มฉลาดมากขึ้น และอนาคตเราจะมี Avatar ในโลก 3D ให้ใช้งาน
ภายในปี 2017 เราจะได้เห็นอุปกรณ์ Virtual Reality (VR) เกิดขึ้นมามากมาย และอุปกรณ์เหล่านั้นจะสามารถติดตามการเคลื่อนไหวของร่างกายได้ดีขึ้น และจะเริ่มมี Virtual Avatar ให้เราได้ใช้แทนตัวเราเองกันในโลก 3D ส่วนในปี 2027 นั้นเราจะได้ใช้งาน Sensor ที่หลากหลายบนระบบ VR และสามารถสร้างภาพเสมือนขึ้นมาในโลกจริงได้ ทำให้มนุษย์เราต้องปรับตัวเรื่องการรับรู้สิ่งต่างๆ บนโลกกันใหม่ ที่จะเพิ่มจากการมองและการฟังในระบบ VR ให้รวมถึงการสัมผัสด้วย
6. Mary L. Gray: การวิเคราะห์ข้อมูลเชิงสังคมจะเปลี่ยนไปด้วย Computer Science และต่อไปเราจะแยก AI กับมนุษย์ที่ให้บริการเราไม่ออกแล้ว
ในปี 2017 วิทยาศาสตร์สังคมและ Computer Science จะผนวกรวมกันและสร้างวิธีการใหม่ๆ ในการวัดค่าต่างๆ ทางด้านวัฒนธรรม, เศรษฐกิจ และการเมืองขึ้นมาภายใต้แนวคิด “Filter Bubbles” ที่จัดหมวดหมู่ข่าวสารและข้อมูลของเพื่อนๆ เราเป็นกลุ่มๆ และนำไปใช้ชี้ว้ดว่าข้อมูลเหล่านี้ส่งผลกระทบอย่างไรต่อชีวิตจริงกันบ้าง ส่วนในปี 2027 กว่า 30% ของผู้ใหญ่ในสหรัฐอเมริกาจะเริ่มทำงานร่วมกับ AI และใช้ AI ช่วยทำหน้าที่ต่างๆ เช่น การให้คำแนะนำด้านภาษีหรือสุขภาพ ซึ่งลูกค้าผู้ใช้งานนั้นไม่อาจจำแนกได้เลยว่าผู้ที่ให้บริการตนเองอยู่นั้นคือมนุษย์หรือ AI
7. Katja Hofmann: เกมจะช่วยให้ AI พัฒนาอย่างรวดเร็ว และต่อไป AI จะอยู่ในทุกส่วนของชีวิตเรา
ในปี 2017 นั้น เกมคอมพิวเตอร์จะกลายเป็นศูนย์กลางของการพัฒนา AI ตัวอย่างเช่นโครงการ Project Malmo (ศึกษาเพิ่มเติมที่ https://www.microsoft.com/en-us/research/project/project-malmo/) นั้นก็จะช่วยให้การทดสอบ AI สามารถทำได้บน Minecraft ทำให้การทดสอบแนวคิดใหม่ๆ สามารถทำได้อย่างรวดเร็วมาก รวมถึงแนวคิดการเปิดให้ AI จำนวนหลายๆ ชุดทำงานร่วมกันด้วย ซึ่งในปี 2027 ต่อไป AI ก็จะมีบทบาทเป็นอย่างมากในการแก้ไขปัญหาต่างๆ ทั่วโลกและสร้างประโยชน์ให้กับสังคมอย่างมหาศาล
8. Nicole Immorlica: วงการเศรษฐศาสตร์ทั่วโลกจะเปลี่ยนไปด้วย Computer Science และข้อมูลปริมาณมหาศาล
ในปี 2017 วงการเศรษฐศาสตร์และ Computer Science จะร่วมมือกันเพื่อพัฒนาเครื่องมือระบบ Machine Learning สำหรับให้เรียนรู้พฤติกรรมกลุ่มย่อยในสังคมเพื่อจัดการกับความสับสนของข้อมูลจำนวนมหาศาล ในขณะที่ปี 2027 นั้นผู้คนจะสามารถร่วมกันช่วยเหลือสังคมได้ด้วยการเปิดข้อมูลชีวิตความเป็นอยู่ให้เหล่านักเศรษฐศาสตร์ได้ศึกษา และอาจมีค่าตอบแทนให้กับอาสาสมัครเหล่านี้ ซึ่งข้อมูลเหล่านี้ก็จะส่งผลให้เกิดการปรับโครงสร้างทางด้านการจัดเก็บภาษีหรือการวางแผนพัฒนาสังคมต่อไปได้
9. Kristin Lauter: Quantum Computing จะทำให้การเข้ารหัสในปัจจุบันใช้งานไม่ได้อีกต่อไป และเทคโนโลยีการเข้ารหัสแบบใหม่ๆ จะต้องเกิดขึ้นมา
ในปี 2017 โซลูชันทางด้านคณิตศาสตร์ใหม่ๆ สำหรับใช้ในการเข้ารหัสจะถูกนำมาใช้เพื่อปกป้องข้อมูลการใช้ยาและข้อมูลพันธุกรรมของผู้ป่วยภายในโรงพยาบาล ซึ่งการเข้ารหัสแบบ Homomorphic นั้นจะถูกนำมาใช้เพื่อให้การนำ Cloud Computing มาจัดเก็บข้อมูลที่มีความละเอียดอ่อนได้อย่างมั่นใจ และทำให้การทำ Preduction หรือ Alert สำหรับเนื้อหาเหล่านี้เป็นจริงขึ้นมาได้ โดย Homomorphic Encryption นี้จะถูกนำมาใช้ก่อนในธุรกิจการเงินเพื่อปกป้องข้อมูลของธนาคารให้ปลอดภัย ส่วนปี 2027 นั้นคณิตศาสตร์จะก้าวหน้าไปเป็นอย่างมาก และจะเข้าสู่ยุคใหม่ของเทคโนโลยีการเข้ารหัส ในขณะที่การมาของ Quantum Computer นั้นจะทำให้การเข้ารหัสที่ใช้อยู่ในปัจจุบันนั้นใช้งานไม่ได้ไปทั้งหมด ซึ่งเมื่อถึงเวลานั้นเทคโนโลยีการเข้ารหัส Quantum ที่กำลังพัฒนากันอยู่นี้ก็จะถูกนำมาใช้ทดแทนการเข้ารหัสในปัจจุบันนี้ไป
10. Kathryn S. McKinely: นักพัฒนา Software จะต้องเรียนรู้ศาสตร์ทางด้านสถิติกันมากขึ้น
ในปี 2017 แนวคิดของการทำ Probabilistic Programming จะก้าวหน้าไปเป็นอย่างมาก และเหล่านักพัฒนาจะสามารถสร้างโมเดลที่ใช้แทนโลกจริงและความไม่แน่นอนขอข้อมูลและการประมวลผลได้ ในขณะที่ปี 2027 นั้นเหล่า Software Engineer จะต้องมีความคล่องแคล่วในการใช้งาน Programming Systems ที่สามารถทำการประมาณค่าและสร้างโมเดลต่างๆ ขึ้นมาได้ด้วยวิธีการทางสถิติ เพื่อให้พัฒนาโปรแกรมสำหรับทำงานร่วมกับ Sensor, Machine Learning และการประมาณค่าต่างๆ ได้เพื่อให้สามารถโต้ตอบกับมนุษย์ได้อย่างถูกต้องแม่นยำมากยิ่งขึ้น
11. Cecily Morrison: เทคโนโลยีผู้ช่วยเสมือนส่วนตัวจะพัฒนาไปได้อย่างรวดเร็วจากการใช้งานของผู้บกพร่องทางสายตา และเด็กๆ จะได้หัดพัฒนาโปรแกรมกันมากขึ้น
ในปี 2017 เหล่าผู้บกพร่องทางสายตานั้นจะกลายเป็นผู้ใช้งานหลักของเทคโนโลยีผู้ช่วยเสมือนส่วนตัว (Personal Agent) และทำให้เทคโนโลยีนี้พัฒนาต่อไปได้อย่างก้าวกระโดด ส่วนในปี 2027 นั้น เด็กๆ ทุกคนรวมถึงเด็กๆ ผู้ที่มีความผิดปกติในร่างกายจะมีเครื่องมือสำหรับใช้เรียนรู้ทางด้านการเขียนโปรแกรม และอีก 20 ถัดจากนั้นไปเด็กๆ เหล่านั้นก็จะสามารถพัฒนาเทคโนโลยีเฉพาะตัวขึ้นมาได้เอง
12. Olya Ohrimenko: เทคโนโลยีด้านความปลอดภัย จะช่วยให้เกิด Application และการนำข้อมูลไปใช้งานได้หลากหลายยิ่งขึ้น
ในปี 2017 Trusted Hardware จะเข้ามาสร้าง Application และเครื่องมือใหม่ๆ ที่มีความปลอดภัยในระดับสูงซึ่งสามารถตอบโจทย์ทั้งผู้ใช้งานและนักพัฒนาได้เป็นอย่างดี ในขณะที่ปี 2027 นั้นความก้าวหน้าของเทคโนโลยีฝั่ง Hardware และการเข้ารหัสก็จะช่วยยกระดับความเป็นส่วนตัวให้มากขึ้นได้อีกขั้น ทำให้การนำข้อมูลส่วนตัวต่างๆ ไปใช้ในการวิเคราะห์หรือประมวลผลนั้นสามารถทำได้เป็นวงกว้างมากยิ่งขึ้น
13. Oriana Riva: Mobile Application จะน้อยลง และจะเปลี่ยนกลายไปเป็น Chatbot มากขึ้น
ในปี 2017 การพัฒนา Mobile Computing จะถูกเปลี่ยนแปลงที่ระดับสถาปัตยกรรมทำให้ระบบต่างๆ สามารถตอบสนองต่อผู้ใช้งานและอุปกรณ์ต่างๆ ได้โดยมี GUI น้อยลง เราจะเห็นการติดตั้ง Software ต่างๆ น้อยลง และ Application ต่างๆ จะถูกเปลี่ยนไปอยู่ในรูปของ Chatbot หรือผู้ช่วยเสมือนส่วนตัวแทน ส่วนปี 2027 นั้นสิ่งต่างๆ ที่อยู่รอบตัวเราจะสื่อสารกันทั้งหมด และเราจะมีระบบผู้ช่วยเสมือนส่วนตัวที่มีความฉลาดและเข้าใจเราอย่างแท้จริง
14. Asta Roseway: Internet of Things จะถูกนำไปใช้ในเชิงเกษตรกรรมร่วมกับ AI
ในปี 2017 เราจะเห็นการนำ Internet of Things (IoT) ไปใช้งานในเชิงการเกษตรที่หลากหลายยิ่งขึ้น โดยเฉพาะการผสมผสานระหว่าง Ubiquitous Sensing, Computer Vision, Cloud Storage, Machine Learning และ Analytics เข้าด้วยกัน ซึ่งบริการเหล่านี้เมื่อนำมาใช้ร่วมกับการออกแบบที่ดีก็จะช่วยให้เหล่าเกษตรกรสามารถติดตามและวิเคราะห์พื้นที่เพาะปลูกในแต่ละแห่งได้ทั้งแบบภาพรวมและเชิงลึก ส่วนในปี 2027 นั้นก็จะเริ่มมีการนำ AI ไปใช้ในการเพาะปลูก เพื่อให้ผลผลิตทางการเกษตรยังคงมีปริมาณตามที่ต้องการได้แม้จะมีภาวะอากาศเปลี่ยนแปลง, น้ำแล้ง หรือภัยพิบัติใดๆ ก็ตาม ซึ่งอนาคตของวงการอาหารในโลกเรานี้หัวใจหลักก็คือการนำทรัพยากรหลักๆ บนโลกมาใช้งานให้ได้คุ้มค่าสูงสุด รวมไปถึงเกิดการอนุรักษ์สิ่งแวดล้อมไปพร้อมๆ กัน
15. Karin Strauss: FPGA, Non-silicon Processor, Near Data Processing, Quantum Computing, DNA Storage และ Near Eye Display
ในปี 2017 เราจะได้เห็นการนำ FPGA มาใช้ในการเร่งการประมวลผลบน FPGA Fabrics และ Cloud มากขึ้น ทำให้การประมวลผลนั้นมีประสิทธิภาพสูงขึ้นและใช้พลังงานน้อยลง นอกจากนี้เราก็จะเห็นการนำ Virtual Reality (VR) และ Augmented Reality (AR) มาใช้งานกันอย่างแพร่หลายทั้งในราคาถูกและแพง รวมถึงจะมี Application และ Content ใหม่ๆ สำหรับอุปกรณ์เหล่านี้โดยเฉพาะ ส่วนในปี 2027 นั้นเราจะได้เห็นเทคโนโลยีอื่นๆ นอกจาก Silicon เกิดขึ้นเป็นจำนวนมาก ทั้ง Carbon Nanotubes และเทคโนโลยีการผลิตในระดับ Molecular รวมถึงสถาปัตยกรรมการประมววลผลแบบใหม่ที่เรียกว่า Near Data Processing ไปจนถึงเทคโนโลยีการประมวลผลแบบใหม่อย่าง Quantum Computing และเทคโนโลยีการจัดเก็บข้อมูลแบบใหม่อย่าง DNA Storage ส่วน AI นั้นก็จะใช้พลังงานน้อยลง และมีเทคโนโลยีแสดงผลแบบใหม่อย่าง Near Eye Display สำหรับแสดงข้อมูล AR และ VR ได้ด้วยคุณภาพสูง
16. Xiaoyun Sun: Computer Vision จะมามีบทบาทต่อการทำงานในอนาคต
ในปี 2017 เทคโนโลยี Computer Vision ที่ใช้ Deep Learning จะก้าวหน้าไปอย่างรวดเร็ว และสามารถจำแนกวัตถุต่างๆ ได้อย่างแม่นยำในระดับเดียวกับมนุษย์ได้ภายในอุปกรณ์ขนาดเล็กที่มีรูปแบบหลากหลาย ส่วนปี 2027 นั้นระบบคอมพิวเตอร์จะสามารถมองเห็นโลกได้ในทุกๆ ภาคส่วนด้วยการนำเทคนิค Deep Learning และ Wide Learning มาผสานกัน เพื่อช่วยมนุษย์ในการทำงานในอุตสาหกรรมต่างๆ ได้อย่างมากมาย
17. Dongmei Zhang: Big Data จะเริ่มรับข้อมูลจากหลากหลายแหล่งมากขึ้น และรับข้อมูลจากผู้ใช้งานโดยตรง
ปี 2017 นั้น Smart Data Discovery จะมาช่วยให้การทำ Data Analytics และ Data Visualization ก้าวหน้าขึ้นไปอย่างรวดเร็ว ทำให้สามารถทำการค้นพบความรู้ใหม่ๆ ได้โดยอัตโนมัติเพื่อช่วยแนะนำผู้ใช้งานได้ทันที รวมถึงจะทำการเรียนรู้จากผู้ใช้งานและนำไปใช้ในการปรับปรุงการวิเคราะห์ได้อย่างต่อเนื่อง ส่วนในปี 2027 นั้นการทำ Data Analytics และ Data Visualization จะสามารถทำได้โดยการผนวกข้อมูลจากหลายแหล่งและหลายรูปแบบในระดับความลึกที่แตกต่างกันได้ ในขณะที่ผู้ใช้งานนั้นจะสามารถเข้าถึงข้อมูลหรือการวิเคราะห์ข้อมูลเหล่านี้ได้ด้วยการใช้ภาษาพูด และสามารถนำข้อมูลเหล่านี้ไปใช้งานได้ในหลากหลายแง่มุมในการใช้ชีวิตและการทำงาน
ก็ต้องติดตามกันต่อไปครับว่าคำทำนายแนวโน้มเหล่านี้จะเป็นจริงมากน้อยแค่ไหนในอนาคต
ที่มา: https://blogs.microsoft.com/next/2016/12/05/17-17-microsoft-researchers-expect-2017-2027/#sm.0007fy9za16y1fea1045co41lnva1
from:https://www.techtalkthai.com/17-technology-predictions-for-2017-2027-by-microsoft-researhcers/