Sam Altman ซีอีโอของ OpenAI พูดคุยกับ Raza Habib ซีอีโอบริษัท Humanloop ถึงแผนการเปิดตัวบริการหรือฟีเจอร์ของบริการใหม่ๆ โดยระบุว่าฟีเจอร์หลายตัวล่าช้าออกไปเพราะปัญหา GPU ไม่เพียงพอที่จะให้บริการ เช่นฟีเจอร์อ่านภาพได้โดยตรงใน GPT-4 (multimodal) ต้องเลื่อนออกไปถึงปี 2024
แผนการเพิ่มฟีเจอร์ GPT-4 ในปีนี้ ได้แก่
- การเร่งความเร็ว GPT-4 และปรับราคาให้ถูกลง
- ขยายขนาด context ให้ใหญ่ขึ้น โดย Altman ระบุว่าน่าจะทำได้ถึงขนาด 100,000-1,000,000 token แต่หากใหญ่กว่านั้นต้องมีงานวิจัยที่ล้ำหน้าไปอีกขั้น
- เปิดให้ finetune โมเดล จากเดิมที่ GPT-3 เคยเปิดให้ลูกค้านำข้อมูลมา finetune ได้แต่ใน GPT-4 ยังไม่เปิด
- รองรับความจำ จากตอนนี้ที่ไคลเอนต์ต้องส่งประวัติการแชตกลับไปยัง OpenAI ทุกรอบ หลังจากนี้จะเปิดให้ OpenAI เป็นคนจำว่าเคยคุยอะไรเอาไว้ก่อนหน้า
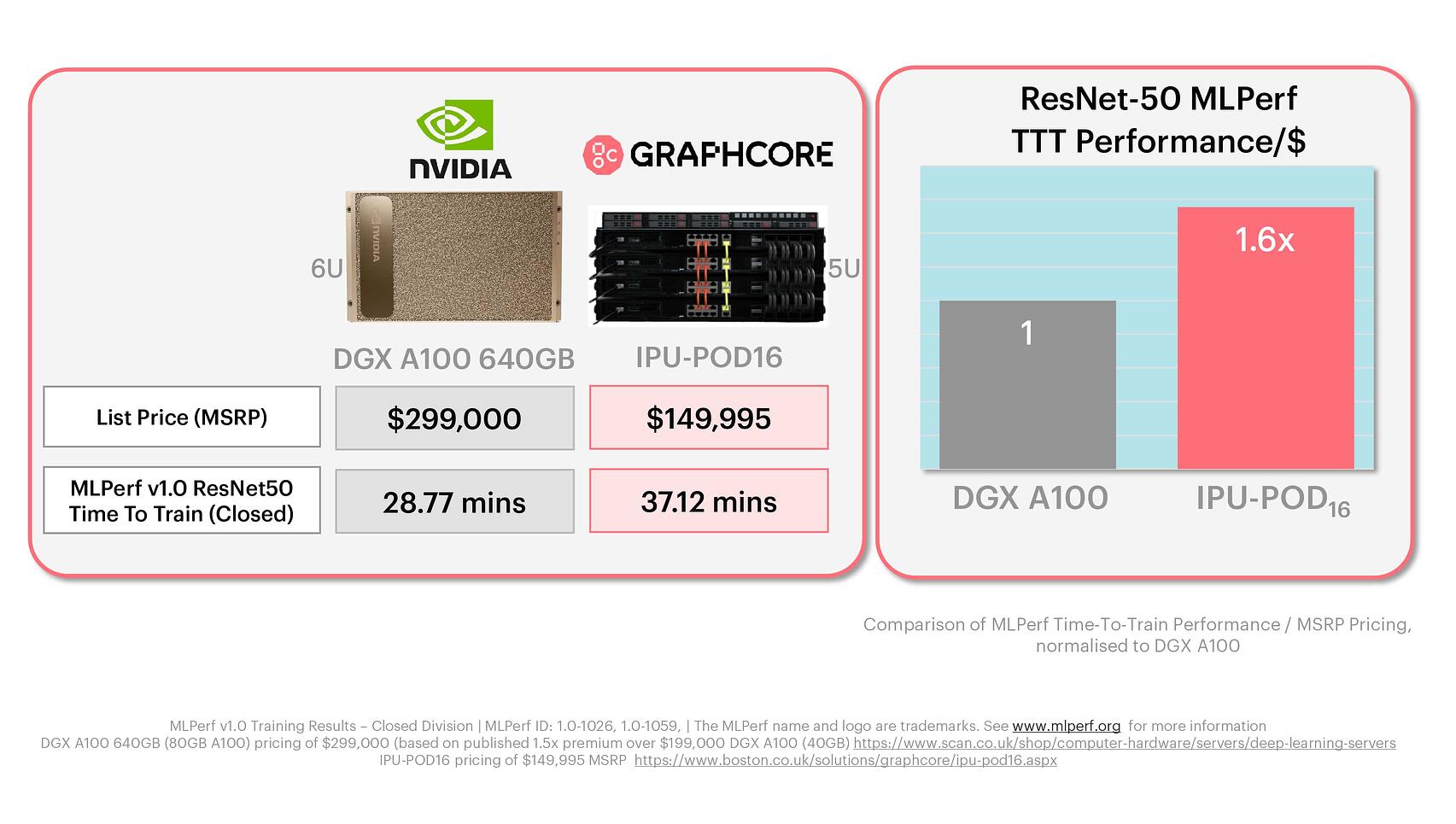
ปัญหาชิปไม่เพียงพอ ทำให้ตอนนี้ OpenAI ต้องจำกัดลูกค้าที่ใช้งาน GPT-4 แบบ 32k context ไว้ก่อน และลูกค้าที่ขอซื้อคลัสเตอร์ส่วนตัวก็ถูกจำกัดไปด้วยเช่นกัน
ที่มา – Humanloop