Tucows เว็บไซต์วัวสองตัว ตำนานแห่งการดาวน์โหลดฟรีแวร์-แชร์แวร์ของอินเทอร์เน็คยุค 90s ประกาศปิดหน้าเว็บส่วนดาวน์โหลด หลังให้บริการมานาน 28 ปี (นับจากปี 1993)
ปัจจุบัน Tucows กลายมาเป็นบริษัทแม่ของธุรกิจด้านโดเมนเนม (เป็นอันดับสองรองจาก GoDaddy) มีเว็บไซต์เกี่ยวกับโดเมนเนมหลายแห่ง เช่น Hover, OpenSRS, Enom, epag.de, ascio.com และขยายไปทำธุรกิจไฟเบอร์ในสหรัฐชื่อว่า Ting ด้วย ตัวบริษัทแม่อยู่ในตลาดหลักทรัพย์ Nasdaq โดยใช้ชื่อย่อว่า TCX
สิ่งที่ Tucows ปิดบริการมีแค่หน้า Tucows Download เท่านั้น ด้วยเหตุผลว่าเปลี่ยนไปทำธุรกิจอื่นหมดแล้ว การรักษาหน้าเว็บเดิมไว้กลายเป็นภาระในการดูแล โดยไฟล์ของซอฟต์แวร์หลายตัวจะถูกบริจาคให้ Internet Archive เพื่อประโยชน์ในการเก็บรักษาประวัติศาสตร์
ชื่อ TUCOWS ในตอนแรกสุด เป็นชื่อย่อของคำว่า The Ultimate Collection of Winsock Software ซึ่งเป็นแหล่งดาวน์โหลดซอฟต์แวร์ตระกูล Winsock ที่โด่งดังในยุคแรกๆ ของอินเทอร์เน็ต
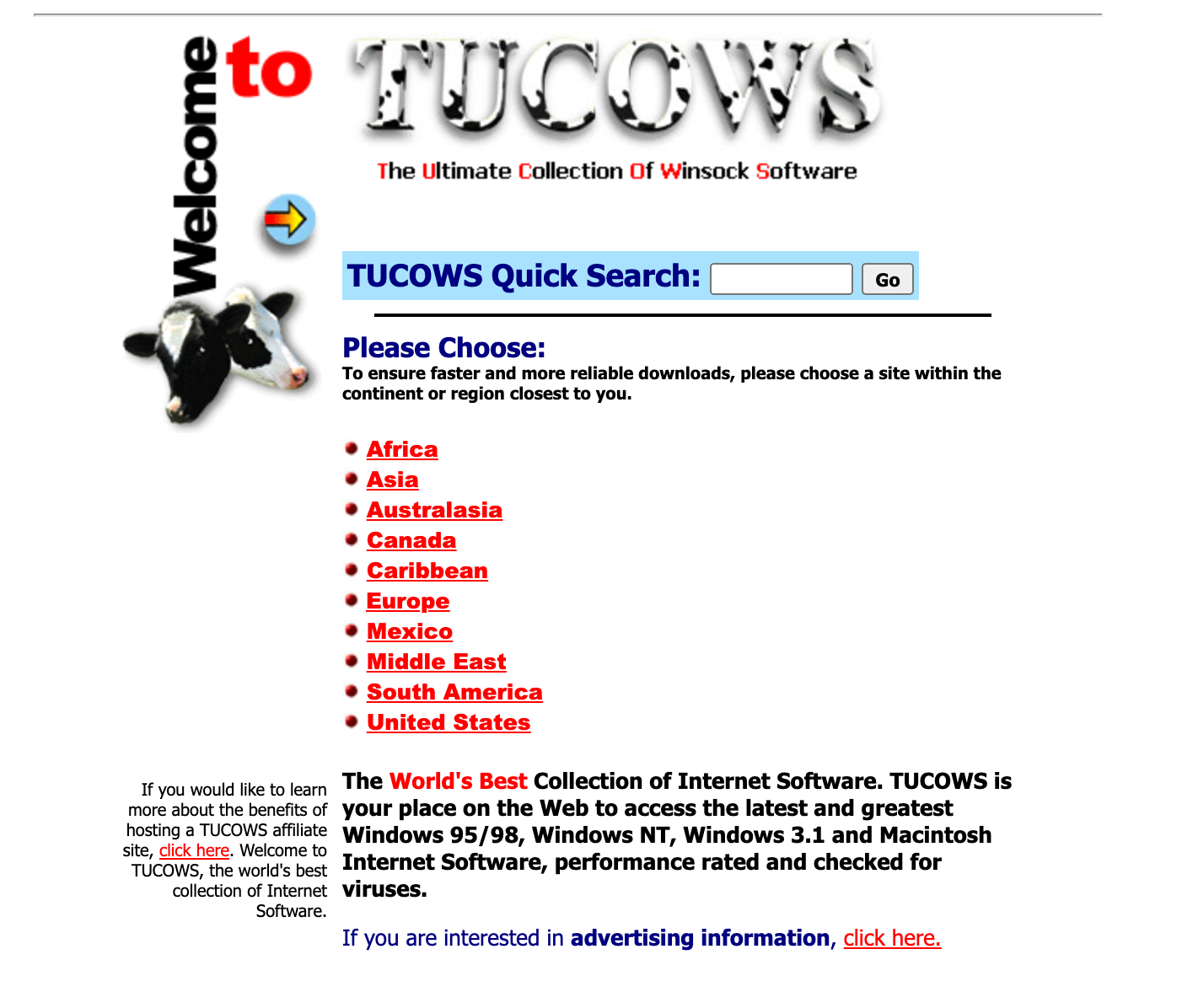
ภาพหน้าแรกของ TUCOWS ในปี 1998
ที่มา – Tucows









{kind=link}